|
设文法G[S]=(VN,VT,P,S),则首字符集为:
FIRST(α)={a | αaβ,a∈VT,α,β∈V *}。
若αε,ε∈FIRST(α)。
由定义可以看出,FIRST(α)是指符号串α能够推导出的所有符号串中处于串首的终结符号组成的集合。所以FIRST集也称为首符号集。
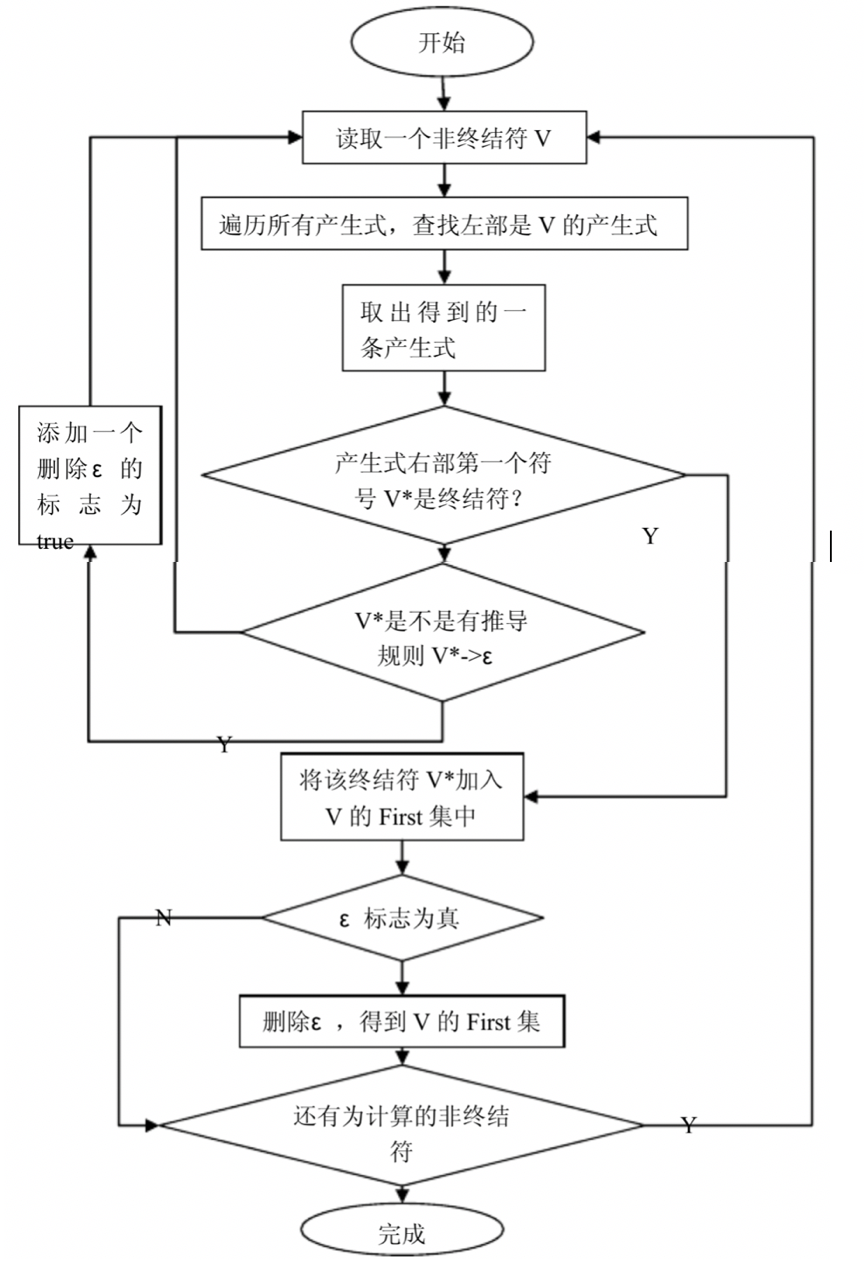
设α=x1x2…xn,FIRST(α)可按下列方法求得:
令FIRST(α)=Φ,i=1;
若xi∈VT,则xi∈FIRST(α);
若xi∈VN;
① 若εFIRST(xi),则FIRST(xi)∈FIRST(α);
② 若ε∈FIRST(xi),则FIRST(xi)-{ε}∈FIRST(α);
i=i+1,重复(1)、(2),直到xi∈VT,(i=2,3,…,n)或xi∈VN且若εFIRST(xi)或i>n为止。
当一个文法中存在ε产生式时,例如,存在A→ε,只有知道哪些符号可以合法地出现在非终结符A之后,才能知道是否选择A→ε产生式。这些合法地出现在非终结符A之后的符号组成的集合被称为FOLLOW集合。下面我们给出文法的FOLLOW集的定义。
设文法G[S]=(VN,VT,P,S),则
FOLLOW(A)={a | S… Aa …,a∈VT}。
若S…A,#∈FOLLOW(A)。
由定义可以看出,FOLLOW(A)是指在文法G[S]的所有句型中,紧跟在非终结符A后的终结符号的集合。
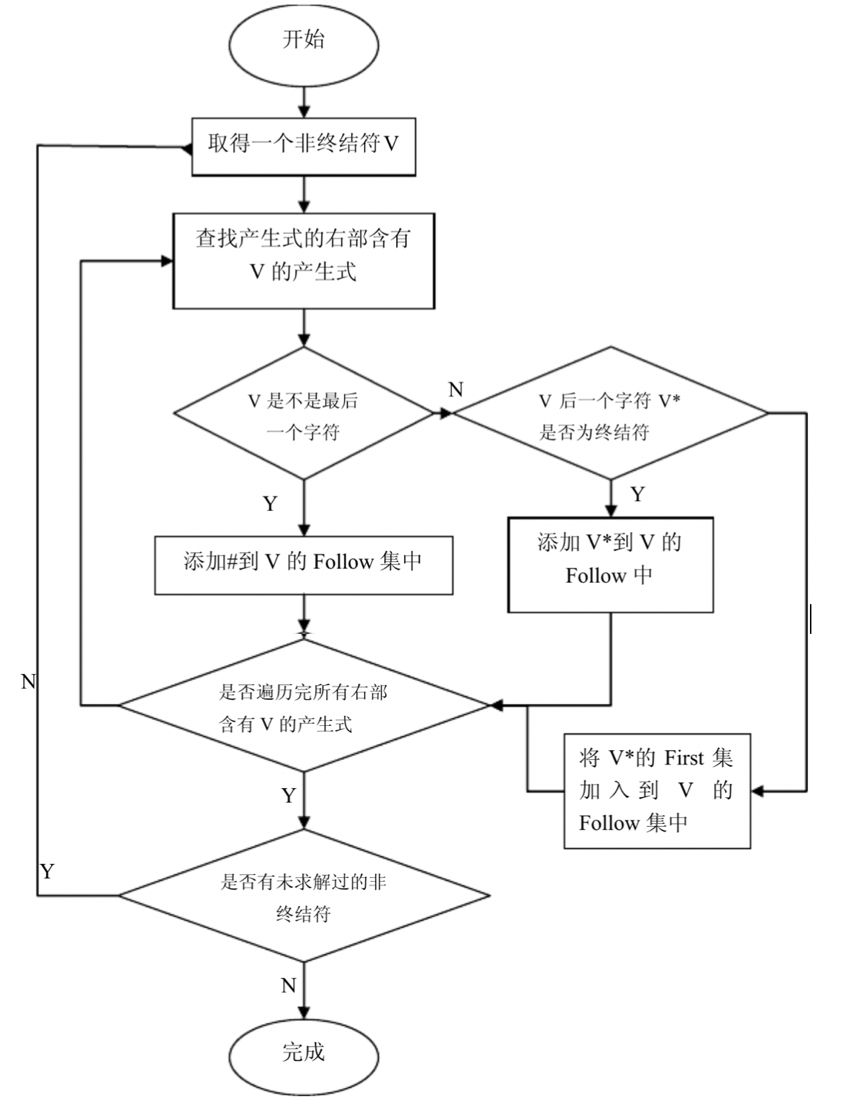
FOLLOW集可按下列方法求得:
对于文法G[S]的开始符号S,有#∈FOLLOW(S);
若文法G[S]中有形如B→xAy的规则,其中x,y∈V *,则FIRST(y)-{ε}∈FOLLOW(A);
若文法G[S]中有形如B→xA的规则,或形如B→xAy的规则且ε∈FIRST(y),其中x,y∈V *,则FOLLOW(B)∈FOLLOW(A);
求First集合的流程图:
求follow集合的流程图:
代码
C++
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196197198199200201202203204205206207208209210211212213214215216217218219220221222223224225226227228229230231232233234235236237238239240241242243244245246247248249250251252253254255256257258259260261262263
#include#include#include#includeusing namespace std;#define MAX 50int NONE[MAX] = { 0 };string strings; //产生式string Vn; //非终结符string Vt; //终结符string first[MAX]; //存放每个终结符的first集string First[MAX]; //存放每个非终结符的first集string Follow[MAX]; //存放每个非终结符的follow集int N; //产生式个数struct STR{ string left; string right;}; void rec(STR *p) //识别Vn和Vt{ int i, j; for (i = 0;i 100) //小写字母放Vt Vt += p[i].left[j]; } } for (j = 0;j = 'A'&&p[i].right[j] 100) Vt += p[i].right[j]; } else { if (Vn.find(p[i].right[j]) > 100) Vn += p[i].right[j]; } } }}void getlr(STR *p, int i) //将产生式的左右部分别放入left,right{ int j; for (j = 0;j100)) //在Vt里,first就是自身 { first[Vt.find(ch)] = ch; return first[Vt.find(ch) - 1]; } if (!(Vn.find(ch) > 100)) //在Vn中的第i个 { for (int i = 0;i 100)) { if (First[Vn.find(ch)].find(p[i].right[0]) > 100) //右侧第一个字符是Vt,加入Vni的first集合中 { First[Vn.find(ch)] += p[i].right[0]; } } if (p[i].right[0] == '#') { if (First[Vn.find(ch)].find('#') > 100) //右侧第一个字符是空,加入Vni的first集合中 { First[Vn.find(ch)] += '#'; } } if (!(Vn.find(p[i].right[0]) > 100)) //右侧第一个字母是Vn { if (p[i].right.length() == 1) //只有一个字母 { string ff; ff = Letter_First(p, p[i].right[0]); //把右侧字母的first集合加入到左侧字母中 for (int k = 0;k 100) { First[Vn.find(ch)] += ff[k]; } } } else //多个字母都是Vn { for (int j = 0;j 100) && (j + 1) |